1
前言
先说明下背景吧,之前学习Scrapy爬了一个网站的美女图片,爬完后发现数量居然有4W多个,此前完全没想到这么多,所以存储时直接放在了一个文件夹,导致现在打开文件夹时巨慢无比,因此想要批量给他们归个类,按不同的文件夹存储。
爬取图片时除了下载了图片外,还通过MySQL存储 了图片的相关信心,其中包括图片类型,如下图:
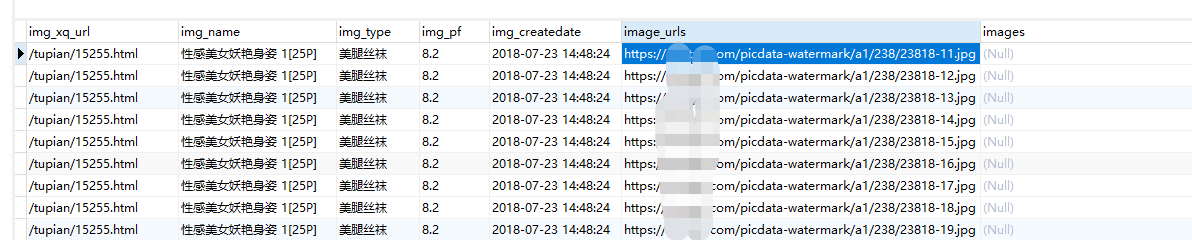
且图片存储的文件名,是使用img_name和image_urls经过处理后拼接而来,很遗憾数据库没有存储:
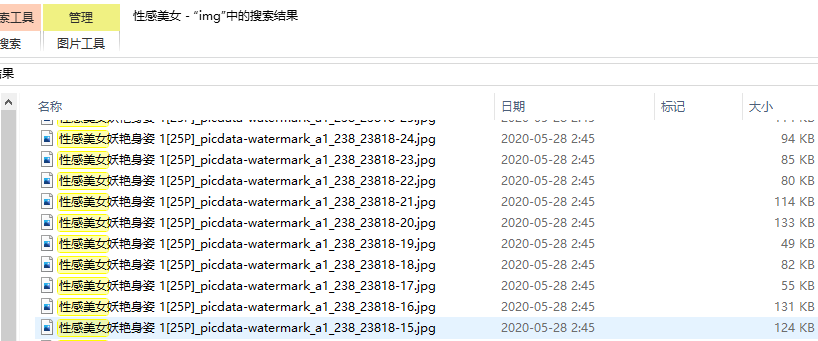
想要按照数据库中的img_type将图片文件分文件夹存储。
目前思路是:
- 更新数据库表,按爬虫存储图片的规则,生成文件名称放在images字段;
- 遍历文件夹,将文件名匹对images字段,匹配上后将文件移入img_type命名的子文件夹;
因为要操作存储图片信息的数据库,我想直接使用爬虫使用的model类,因此将脚本放在scrapy项目的根目录下了,和pipiline.py同级目录,使用到的model相关内容可以参考另一篇文章《Scrapy的pipelines使用sqlalchemy》,model相关内容如下:
#model包的__init__.py文件
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
#创建对象基类
Base = declarative_base()
#初始化数据库连接
engine = create_engine('mysql+pymysql://root:98256582@localhost:3306/get_ais?charset=utf8',pool_size=100)
#返回数据库会话
def loadSession():
Session = sessionmaker(bind=engine)
session = Session()
return session#model包下定义图片model的模块
from sqlalchemy import String,Column,DateTime,Text,Integer
from . import Base
class IMG(Base):
__tablename__ = 'ais_img'
img_xq_url = Column(String(100),nullable = True)
img_name = Column(String(100),nullable = True)
img_type = Column(String(20),nullable = True)
img_pf = Column(String(10),nullable = True)
img_createdate = Column(DateTime,nullable = True)
image_urls = Column(String(100),primary_key = True,nullable = False)
images = Column(String(200),nullable = True)
更新数据库
确保脚本文件和model包在同一目录,否则要调整import的方法,脚本及解释如下:
#引入model包__init__.py里面获取数据库连接的函数
from model import loadSession
#引入model里面存储图片信息的模型类
from model.ais_img import IMG
#跟爬虫同样逻辑处理文件名,使用了正则表达式
import re
#由于处理含汉字的url转换的包和函数
from urllib.parse import unquote
#获取数据库连接
session = loadSession()
#查询出表里面所有的对象,每个对象是一个obj,相当于一行数据
ru_list = session.query(IMG).filter(1==1).all()
#一个个对象循环,拿出img_name和image_urls进行处理和拼接
for ru in ru_list:
#使用obj.column方式,获取字段的值
img_name = ru.img_name
image_urls = ru.image_urls
#用_拼接name和url里面除网址外的部分
zh = img_name+'_'+unquote("".join(re.findall(".com/([\w\W]+)",image_urls)))
#用正则替换掉不能作为文件名的特殊符号
images=re.sub(r'[\/:*?"<>|]', '_',zh)
#将拼接好的文件名更新到对象的images字段
ru.images=images
#提交更新
session.commit()
print(img_name,image_urls,images)执行这个脚本,会一行行处理数据,4W多行大概花了4个小时,确实好慢;如果不是因为url的处理以及文件名特殊字符的处理在SQL里面太过麻烦,直接写SQL语句处理会快得多。
匹对移动图片
现在数据库已有文件的名字,那么我们可以开始遍历文件夹里面的文件,并按文件名在数据库查出图片类型,进而移动文件到图片类型命名的文件夹。
python操作文件主要使用os,shutil这两个自带的包,我们先写一个移动文件的函数:
import os,shutil
#移动文件参数为:文件目录、文件名称、文件全路径名称
def move_img(s_path,filename,data_fullname):
#有些文件在数据库可能找不到对应的记录,为了避免超出list长度的错误中断程序执行,加一个异常捕获
try:
#获取数据库连接
session=loadSession()
#获取文件名对应的数据库obj,结果是一个list,因为有可能查到多行数据
#filter还可以使用like模糊查询filter(IMG.images.like(filename+'%'))
img_obj = session.query(IMG).filter(IMG.images==filename).all()
#拼接文件目录和图片类型,形成新的文件目录,如果数据库有多个同名文件记录,则使用第一个
type_dir = os.path.join(s_path,img_obj[0].img_type)
print('新文件路径为:%s'%type_dir)
#如果新路径不存在,则创建
if not os.path.exists(type_dir):
os.mkdir(type_dir)
#shutil.move移动文件,第一个参数是文件全路径名称,第二个参数是路径时移动到该路径,是全路径名称时重命名并移动到该路径
shutil.move(data_fullname,type_dir)
#关闭数据库连接
session.close()
except Exception as e:
print('错误信息%s'%e)接下来循环图片所在目录,然后每个文件都对应执行上面这个函数即可:
#遍历文件夹获取文件名的函数
def get_filename(s_path):
#遍历文件夹,获取文件夹下所有文件名和文件夹
list=os.listdir(s_path)
for data in list:
#拼接目录和目录下的对象,形成全路径
data_fullname=os.path.join(s_path,data)
#isfile判断是否为文件,为文件则调用移动文件的函数
if os.path.isfile(data_fullname):
print('文件为:%s'%data_fullname)
print(data)
move_img(s_path,data,data_fullname)
最后写一个文件入口判断,代入文件夹路径,调用get_filename()函数:
if __name__ == "__main__":
get_filename(r'C:\06Python\Scrapy\get_ais\get_ais\filedata\img')执行完成后,发现图片以及按需求分类存放了,还剩少数数据库没记录的,手工处理下即可。



