前言
自从“爬虫学的好,监狱进得早”事件发生后,好久没玩Scrapy了。恰巧今天看到一个很心动的视频想要弄下来,而刚建好的Bolg急需内容填充,因此决定边爬边写,顺便复习一下Scrapy基础知识并记录下来。
为维护目标网站利益,因此网站地址果断打码。
再次申明,本文内容仅供技术交流,各位同学请深刻理解“爬虫学的好,监狱进得早”的含义,务必做一位遵纪守法的好网民。
一、开始项目
环境准备
自从用了Python虚拟环境后就离不开了,务必每个项目建一个虚拟环境(Python虚拟环境安装请自行百度,等有空我再把笔记搬到Bolg):
mkvirtualenv py-scrapy-zphgc创建虚拟环境后会自动激活并进入该虚拟环境,接下来安装我们的爬虫框架Scrapy:
pip install scrapy然后进入要保存项目的目录,创建Scrapy项目,并进入项目目录新建一个爬虫:
cd C:\06Python\Scrapy
#创建项目
scrapy startproject get_zphgc
cd get_zphgc
#新增爬虫
scrapy genspider get_sp XXXXX.COM准备就绪,用VS Code打开项目爬虫文件,可以看到如下内容:
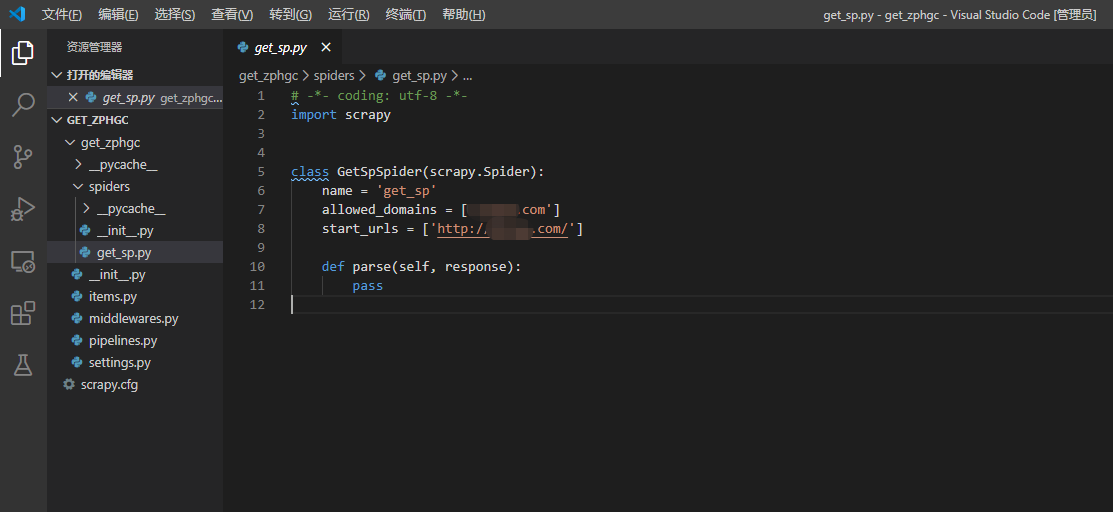
- name是爬虫名称
- allowed_domains是爬虫爬取的域名范围,超出此范围不会请求
- start_urls是开启爬虫后请求的第一个页面
- parse函数是接收到第一个请求的回复后执行的动作
页面分析
首先打开我们要开始爬的页面,是一个视频列表,大致样式如下图( 借用虎牙图片一用 ):
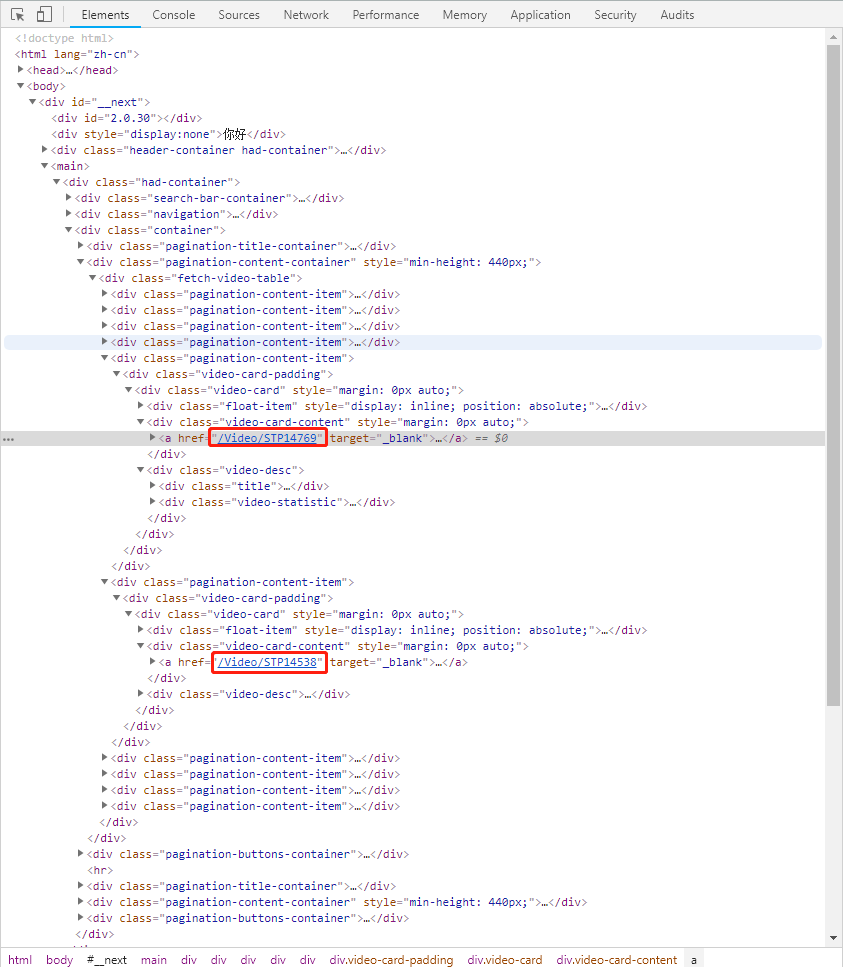
按F12打开Chrome开发者工具,用左上角指针点击一个视频,展开后可以看到列表视频网址,这就是我们的第一个目标,获取视频详情的网址:
访问视频详情网址,可以进入到视频播放页面( 继续借用虎牙页面图片):
同样按F12打开开发者工具,可以找到视频的来源地址: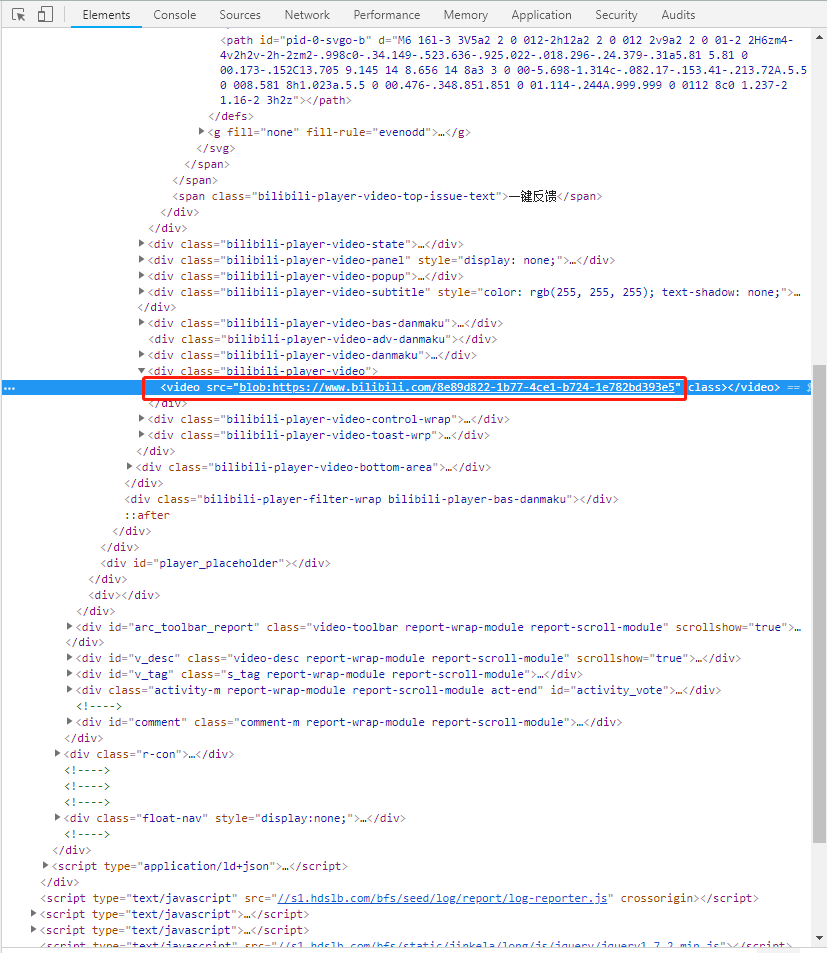
这是我们第二个目标,视频播放的源地址。
通常如果是爬图片的话,我们已经可以用这个地址去下载图片了,但是我们发现这个视频的地址并不是常规的HTTP地址,前面加了一个‘blob’,百度了一下‘blob’是一种特殊的反爬手段,可以查看这篇文章:( https://blog.csdn.net/xingyun89114/article/details/80699527 )
一、问题场景
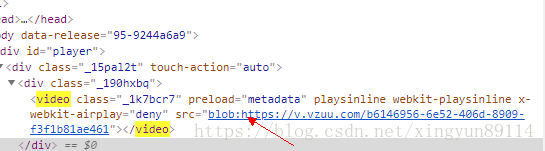
想下载知乎视频资源,却发现视频链接是这个样子的
blob:https://v.vzuu.com/b6146956-6e52-406d-8909-f3f1b81ae461
当时一脸懵比啊 ~难道blob:https是什么牛逼的新协议?于是进行了一番探索
二、探寻结论
结论就是blob:https并不是一种协议,而是html5中blob对象在赋给video标签后生成的一串标记,blob对象对象包含的数据,浏览器内部会解析;
在web容器中的页面代码
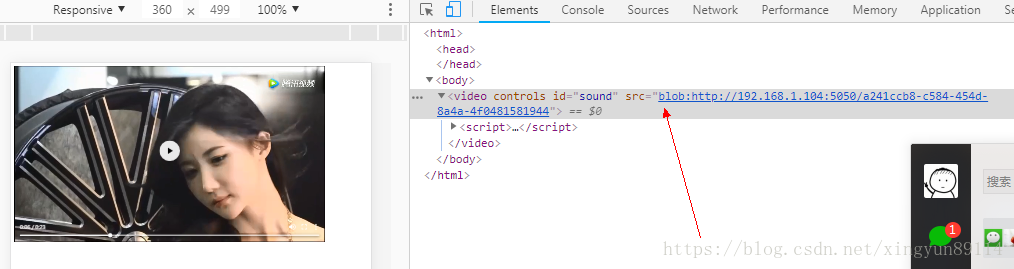
浏览器访问后的页面代码
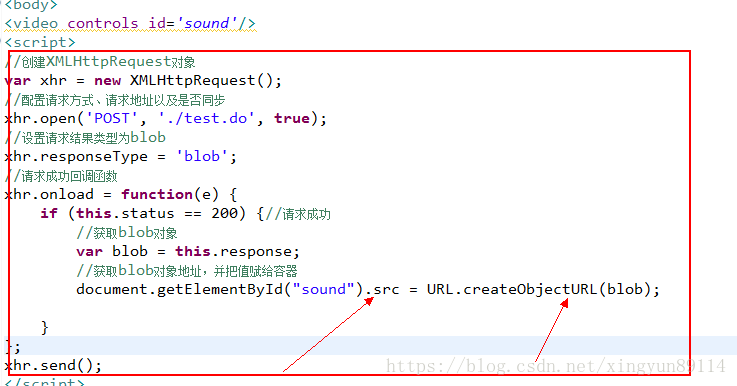
这是因为在浏览器中执行了如下js
三、关于资源下载
很多小伙伴查找这个问题,是为了下载视频资源,
资源的真实下载链接可在chrome的调式模式的network中找到,
但有种资源比较特殊,即m3u8格式的资源
这种格式的视频会被分解成很多个小片段,这个链接下载的是一个包含多个小视频(ts格式的视频)的链接集合,这样做的目的是:
1、可以方便切换分辨率(多个ts格式的视频支持无缝流畅播放,MP4不行);
2、可能就是防止下载吧;
————————————————
版权声明:本文为CSDN博主「云涛89114」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xingyun89114/article/details/80699527

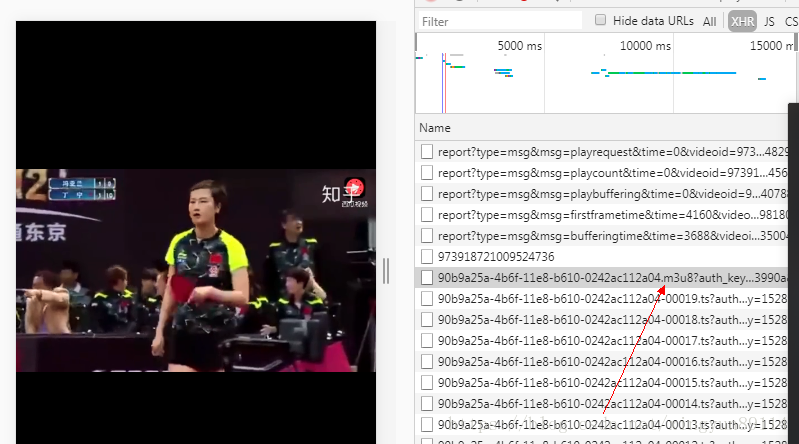
后面查看了多篇文章后发现,并不是所有的blob:http在network里面看到的都是m3u8格式,有的直接就是可以播放的.flv格式,如果直接是.flv格式就可以直接获取地址下载来播放。
如果是m3u8格式,那么下载来的文件是一个文本文件,里面包含了多个.TS格式视频短片的下载地址,可以解析这个m3u8文本文件,访问里面的url下载.TS文件,然后拼接合并.TS文件形成完整的视频。本次我要爬的视频正好是这种形式。
二、开始爬取
经过上面分析,知道总共分三步获取到视频:
获取视频详情页URL列表;
获取视频源址,并组合成m3u8下载链接,下载m3u8文件;
解析m3u8文件,下载包含的.TS视频片段;
获取视频URL列表
首先我们进入./spiders文件夹,打开我们新增的爬虫get_sp.py,先修改开始页面为视频列表页面。
然后编写访问列表后对页面response处理的Parse函数,写法和注解直接见代码:
#获取视频详情URL函数
def parse(self, response):
#使用logging模块做日志记录
logging.info('开始回调函数,请求为%s'%response)
#由于获取到的是绝对路径,需要拼接上域名才能访问,因此先定义前面要拼接的地址
baseurl='http://XXXX.COM/'
#使用try/except捕获错误
try:
#使用Xpath解析网页内容,返回包含目标信息的页面列表
resp=response.xpath('//*[@style="table-layout:fixed;"]/tr/td[@style="text-align:left;line-height:25px; FONT-SIZE:11pt "]')
#print('获取到的内容为:',resp)
#循环列表,解析出每一块包含的视频标题、视频详情URL
for list in resp:
print(list)
#xpath解析初出视频标题
wz_title=list.xpath('h3/a/text()')
print('文本为:',wz_title.extract())
#xpath解析出视频URL
wz_href=list.xpath('h3/a/@href').extract()
print('连接为:',wz_href)
#self.get_tid(baseurl+wz_href[0],wz_title)
#如果URL存在,则执行获取m3u8文件的get_tid()函数
if wz_href:
yield Request(baseurl+wz_href[0],callback=lambda response,wz_title=wz_title:self.get_tid(response,wz_title[0]))
#获取页码,爬取其他列表页面
ym_url_resp=response.xpath('//*[@class="pages cc"]/a/@href').extract()
print('页面地址为:',ym_url_resp)
for url_resp in ym_url_resp:
#使用本函数再处理查找到的其他列表页面
yield Request(url=baseurl+url_resp,callback=self.parse)
except EOFError as e :
print('回调函数失败',e)获取m3u8文件
上面获取到列表后调用了get_tid()函数,get_tid()函数就是接下来要定义的下载m3u8文件的函数,本案例中network中可看到的m3u8下载链接是使用一个m3u8前缀域名加上视频ID拼接而来,因此我们先通过视频源址截取到视频ID,然后拼接前缀形成m3u8下载链接,具体内容和注解如下:
#获取文章m3u8下载链接的ID,组合后返回链接
def get_tid(self,response,wz_title):
print('开始获取m3u8链接!')
try:
#同样从页面获取到的也只是ID,我们要拼接域名才能访问,故先定义域名
m3u8_url='https://m3u8.XXXX.com/'
#通过Xpaht获取视频详情页面的视频源址
resp=response.xpath('//div[@class="f14"]//iframe/@src')
if resp:
print('获取包含ID的地址:',resp)
resp_str=resp[0].extract()
#从源址中截取视频ID
id_str=resp_str[resp_str.rfind('id=')+3:]
print('m3u8链接和文章标题为:',m3u8_url+id_str,wz_title.extract())
#用ID和前缀拼接成视频m3u8文件下载链接,下载文件,下载文件,并调用download()函数
if m3u8_url+id_str:
yield Request(url=m3u8_url+id_str,callback=lambda response,name=wz_title.extract():self.download(response,name))
except EOFError as e :
print('m3u8下载链接获取失败!',e)解析m3u8文件,下载.TS视频片段
最后定义解析m3u8文件并下载.TS视频片段的函数,由于要保存文件,添加了目录的判断,具体内容和注解如下:
#根据m3u8链接,解析TS文件链接,并访问下载TS文件
def download(self,response,name):
#获取当前目录
download_path = os.path.abspath('.')
#拼接下载存储目录
down_path=os.path.dirname(download_path)+"\download"
print('存储路径:%s'%down_path)
#如果目录不存在则创建目录
if not os.path.exists(down_path):
os.mkdir(down_path)
print('创建目录',down_path)
all_content = response.xpath('.').extract()
#获取到TS文件下载地址
url_lists=re.findall(r'https.+?ts',all_content)
print('下载地址列表:%s'%url_lists)
#循环访问地址
for index,ts_url in enumerate(url_lists):
#每次访问延迟2-3秒
yc = random.uniform(2, 3)
time.sleep(yc)
resp=requests.get(ts_url)
#存储下载的文件
with open(down_path+'\\'+name+str(index)+'.ts','ab') as f:
f.write(resp.content)
print('下载完成:%s'%name+str(index))
f.flush()结尾
准确来讲,本案例并没有使用到Scrapy框架太多东西,本案例中数据的传输,文件的下载都是直接写在了spider里面,而Scrapy框架有专门的Items模块来传输数据,有专门的pipelines模块来处理数据清洗和下载,spider原来只是来处理请求和解析网页。
更规范的Scrapy框架用法,后续将使用一个小说下载的案例来展示,敬请期待。



